
Red Agent Swarms for Testing Customer-Facing AI Agents
LLM applications have a semi-infinite attack surface, and they are notoriously hard to secure without breaking the user experience.
AI
LLM
AI Safety
Learn how to build an end-to-end pipeline for automatically generating quiz questions from a corpus of technical documentation using large language models and retrieval augmented generation on the Databricks Lakehouse Platform.

Engaging quizzes with well-written questions and distractors are one of the most effective ways to help people learn and retain knowledge. However, manually creating a large volume of high-quality quiz questions is a tedious and time-consuming process, even for subject matter experts.
Recent advancements in large language models (LLMs) open up an exciting possibility: what if we could automatically generate complete quizzes, including realistic incorrect answer choices, simply by ingesting a corpus of training material into an LLM? Furthermore, could we build a pipeline to generate quizzes on specific topics by semantically searching the training corpus for relevant passages to provide as context to the LLM?
In this blog post, we'll walk through an end-to-end implementation of this idea using the Databricks Lakehouse Platform and several popular open source libraries, including Databricks VectorSearch, Foundational Models, MLFlow and more.
We'll first create a knowledge corpus by ingesting Databricks documentation and splitting it into chunks that we store in a vector search index. Then we'll use LangChain to define a set of "agents" that perform the steps of the quiz generation process. Finally, we'll explore how output parsers and retry logic can validate the quality and improve the reliability of the generated quizzes.
Let's start with an overview of the quiz generation pipeline architecture:
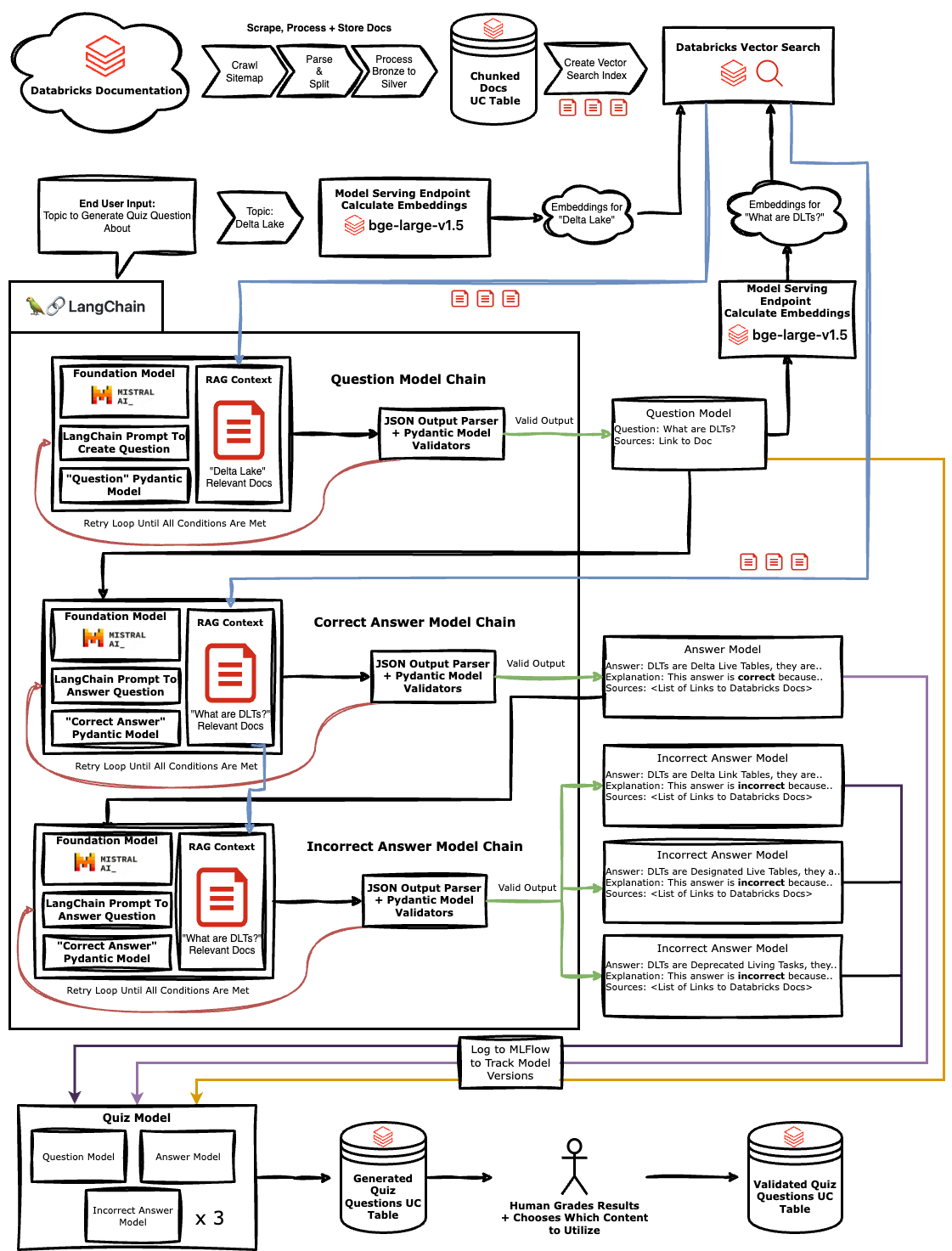
There are a few key components:
With the high-level architecture in mind, let's dive into some of the key aspects of the implementation.
The first step is to take the raw HTML content, clean it up and split it into meaningful chunks that can be searched and used as context for the LLM. We use Beautiful Soup to parse the HTML, langchain's RecursiveCharacterTextSplitter to split on headers and enforce a maximum chunk length, and the BGE Large embedding model to generate embeddings.
def split_html_on_h2(html):
h2_chunks = html_splitter.split_text(html)
chunks = []
previous_chunk = ""
# Merge chunks together to add text before h2 and avoid too small docs.
for c in h2_chunks:
content = c.metadata.get('header2', "") + "\n" + c.page_content
if len(tokenizer.encode(previous_chunk + content)) <= max_chunk_size/2:
previous_chunk += content + "\n"
else:
chunks.extend(text_splitter.split_text(previous_chunk.strip()))
previous_chunk = content + "\n"
if previous_chunk:
chunks.extend(text_splitter.split_text(previous_chunk.strip()))
# Discard chunks that are too short
return [c for c in chunks if len(tokenizer.encode(c)) > min_chunk_size]A few key things to note in this chunking logic:
This chunking + embedding strategy is covered much more in depth in the RAG LLM Demo that Databricks provides.
At the core of the quiz generation process is a set of carefully engineered prompts that instruct the LLM on how to perform each step. Let's take a look at the prompt template for a key part of the process - generating 3 incorrect answers or "distractors", while ensuring each of them is unique:
incorrect_answers_template = '''
Based on the provided context, generate a realistically incorrect answer to the question.
The incorrect answer should be plausible enough to mislead someone without a thorough understanding of the topic but must be definitively incorrect.
Instructions:
1. **Correct Answer:** You have already provided the correct answer, which you should not repeat.
2. **Plausibility:** The incorrect answer should be realistic and convincing, mirroring the correct answer in length and format.
3. **Uniqueness:** Ensure your response is unique compared to previous incorrect answers provided.
4. **Structure:** Follow the format and complexity of the correct answer to maintain consistency. The answer should be short and concise.
Examples of good incorrect, but realistic answers you should give as a response:
- If the question is "What is the primary function of Delta Lake in a data engineering pipeline?", an appropriate incorrect, but realistic answer would be "Delta Lake is primarily used for visualizing data in interactive dashboards, allowing users to create real-time charts and graphs for data analysis." because it is false, but also a realistic answer for this question.
- If the question is "How does Apache Spark optimize data processing tasks?", an appropriate incorrect, but realistic answer would be would be "Apache Spark optimizes data processing tasks by using a traditional disk-based approach, where all data is stored on disk and processed sequentially."
Correct Answer You Gave Before (Do NOT Repeat): {correct_answer}
Incorrect, But Realistic Answers You Already Gave (Do NOT Repeat): {previous_answers}
Format Instructions: {format_instructions}
Context: {context}
Question: {question}
Generate a realistically incorrect answer:
'''A few key techniques are used to elicit the desired outputs:
{format_instructions} variable is a placeholder for specifying any additional formatting requirements, like the desired output structure (e.g., numbered list, JSON format). This allows programmatically enforcing a consistent, easily parseable output schema. Further down we show how these format instructions are dynamically generated from the JSONOutputParser built on top of the incorrect answer Pydantic model.Of course, prompt engineering is still more art than science, and these examples were arrived at through extensive iteration and refinement. Prompt composition is an area of active research and tooling to help make this process more systematic is rapidly evolving. You should experiment with a variety of techniques and prompt formats depending on the use case you are trying to solve.
Simply getting the LLM to generate responses with the desired fields is not sufficient - we also need to programmatically validate that the outputs match the expected schema. This is where Pydantic models come in handy:
class QuestionModel(BaseModel):
question: str = Field(description="question to be used for generating correct and incorrect but plausible answers")
source: List[AnyUrl] = Field(description="a list of the top 2 most important links to the source material from the context provided that was used to generate the question")
@validator('question')
def validate_question(cls, value):
if not value or len(value) < 10:
raise ValueError("Question is too short or missing.")
if len(value) > 500:
raise ValueError("Question is too long winded. Should be shorter and more concise.")
return value
@validator('source')
def validate_source(cls, value):
if not value or len(value) > 3:
raise ValueError("Too many links returned, should be 2 max, 3 is allowed if necessary, 4 will throw an error.")
return value
class AnswerModel(BaseModel):
answer: str = Field(description="correct answer to the question that is short and concise")
explanation: str = Field(description="an explanation describing why the answer provided is correct")
source: List[AnyUrl] = Field(description="a list of the top 2 most important links to the source material from the context provided that was used to answer the question")
@validator('answer')
def validate_answer(cls, value):
if not value or len(value) < 1:
raise ValueError("Answer is too short or missing.")
return value
@validator('explanation')
def validate_explanation(cls, value):
if not value or len(value) > 500:
raise ValueError("Explanation is too long winded. Needs to be shorter and more precise.")
return value
@validator('source')
def validate_source(cls, value):
if not value or len(value) > 3:
raise ValueError("Too many links returned, should be 2 max, 3 is allowed if necessary, 4 will throw an error.")
return value
class IncorrectAnswerModel(BaseModel):
incorrect_answer: str = Field(description="incorrect but plausible answer to the question that are short and concise")
explanation: str = Field(description="an explanation describing why the incorrect answer provided is incorrect")
source: List[AnyUrl] = Field(description="a list of the top 2 most important links to the source material from the context provided that was used respond to this ask")
@validator('incorrect_answer')
def validate_incorrect_answer(cls, value, values):
if not value or len(value) < 3:
raise ValueError("Incorrect answer should be longer than 3 characters")
return value
@validator('explanation')
def validate_explanation(cls, value):
if not value or len(value) > 500:
raise ValueError("Explanation is too long winded.")
return value
@validator('source')
def validate_source(cls, value):
if not value or len(value) > 3:
raise ValueError("Too many links returned, should be 2 max, 3 is allowed if necessary, 4 will throw an error.")
return value
class TopicModel(BaseModel):
topic: str = Field(description="an important topic that can be used to create questions and can be described in 5 words or less")
@validator('topic')
def validate_topic(cls, value):
if not value or len(value) < 1:
raise ValueError("Topic is too short or missing.")
return value
class QuizModel(BaseModel):
topic: TopicModel
question: QuestionModel
correct_answer: AnswerModel
incorrect_answers: List[IncorrectAnswerModel]These pydantic models define the expected structure of the outputs, along with validation logic to check properties like minimum/maximum string lengths and number of incorrect answers. An important fact to highlight is the descriptions of the fields effect the eventual output.
These models are then passed to the JSONOutputParser base parser, then are passed into the LLMChain:
from langchain_core.output_parsers import JsonOutputParser
question_parser = JsonOutputParser(pydantic_object=QuestionModel)
answer_parser = JsonOutputParser(pydantic_object=AnswerModel)
incorrect_answer_parser = JsonOutputParser(pydantic_object=IncorrectAnswerModel)
topic_parser = JsonOutputParser(pydantic_object=TopicModel)We can now look at what is passed into the {format_instructions} parameter in the prompt, which is an output of the JsonOutputParser class:
question_parser.get_format_instruction()
'The output should be formatted as a JSON instance that conforms to the JSON schema below.\n\nAs an example, for the schema {"properties": {"foo": {"title": "Foo", "description": "a list of strings", "type": "array", "items": {"type": "string"}}}, "required": ["foo"]}\nthe object {"foo": ["bar", "baz"]} is a well-formatted instance of the schema. The object {"properties": {"foo": ["bar", "baz"]}} is not well-formatted.\n\nHere is the output schema:\n```\n{"properties": {"question": {"title": "Question", "description": "question to be used for generating correct and incorrect but plausible answers", "type": "string"}, "source": {"title": "Source", "description": "link to the source material from the context provided that was used to generate the question", "minLength": 1, "maxLength": 65536, "format": "uri", "type": "string"}}, "required": ["question", "source"]}\n```'Beyond adding further instructions + enforcing schema at the prompt level, the models can also be used to validate + parse the raw output of the model's. This can be utilized to test the output matches the intended format, and affords an opportunity to retry a phase if the model returns an invalid output.
Here is an excerpt from the main logic that generates quiz components, showing how the pydantic model can be used for this validation + retry logic. This function encapsulates the full quiz generation flow:
By breaking down the generation into discrete steps with well-defined inputs and outputs, the pipeline is much easier to test, refine, and maintain compared to a single monolithic generation.
It's also worth noting the "fail fast" approach to error handling - if a generation step produces an invalid output, the pipeline skips that question entirely rather than attempting to salvage it. This helps improve the overall quality of the generated quizzes, at the cost of occasionally producing quizzes with fewer questions. The number of retries before skipping is a tunable parameter to balance quality vs. throughput.
def generate_quiz_components(topic, log=False):
context = vectorstore.get_relevant_documents(topic.topic)
max_question_retries = 5
retries = 0
while(retries < max_question_retries):
question_response = retry_chain(question_chain, context=context, topic=topic.topic)
try:
question = QuestionModel(**question_response)
if log:
log_run(run_name, {'topic': topic.topic}, question_response, question_chain, '_question_model')
break
except ValidationError as e:
print(f"question validation error: {question_response}")
print(f"Retrying {retries} more times")
retries +=1
if retries == max_question_retries:
return 'stuck_in_loop'
except TypeError as e:
print(f"question validation error: {question_response}")
print(f"Retrying {retries} more times")
retries +=1
if retries == max_question_retries:
return 'stuck_in_loop'
# logic for correct answers and incorrect answers
...
quiz = QuizModel(
topic=topic,
question=question,
correct_answer=correct_answer,
incorrect_answers=incorrect_answers
)
return quiz.dict()
Now, we specify a list of topics (or use the model to generate new ones), and let the pipeline generate quiz questions for each one. After, it stores each successfully generated + validated quiz question in a Unity Catalog table tagged with the versions of the question, answer and incorrect answer model that was used to generate it.
topics = [
TopicModel(topic='Unity Catalog'),
TopicModel(topic='MLFlow'),
TopicModel(topic='Databricks Marketplace')
]
quiz = []
first_topic = True
for topic in topics:
if first_topic and model_has_changed:
quiz_question = generate_quiz_components(topic, True)
question_model_id = get_latest_model_version_id(model_name + '_question_model')
answer_model_id = get_latest_model_version_id(model_name + '_answer_model')
incorrect_answer_model_id = get_latest_model_version_id(model_name + '_incorrect_answer_model')
if quiz_question != 'stuck_in_loop':
first_topic = False
else:
quiz_question = generate_quiz_components(topic, False)
if quiz_question != 'stuck_in_loop':
quiz.append(quiz_question)
store_quiz_question_in_table(topic.topic, run_id, question_model_id, answer_model_id, incorrect_answer_model_id, quiz_question){
"topic": {
"topic": "Databricks Marketplace"
},
"question": {
"question": "What types of assets can be shared and accessed on Databricks Marketplace?",
"source": [
"https://docs.databricks.com/en/marketplace/index.html",
"https://docs.databricks.com/en/release-notes/product/2024/january.html"
]
},
"correct_answer": {
"answer": "Datasets, Databricks notebooks, Databricks Solution Accelerators, and machine learning models can be shared and accessed on Databricks Marketplace. Datasets can be in the form of tabular or non-tabular data.",
"explanation": "The context states that Databricks Marketplace allows sharing and access to datasets, Databricks notebooks, Databricks Solution Accelerators, and machine learning models. It also mentions that datasets can be tabular or non-tabular data, which are typically made available as catalogs of tabular data, or in the form of Databricks volumes respectively.",
"source": [
"https://docs.databricks.com/en/marketplace/index.html",
"https://docs.databricks.com/en/release-notes/product/2024/january.html"
]
},
"incorrect_answers": [
{
"incorrect_answer": "On Databricks Marketplace, users can only share and access machine learning models and Databricks notebooks. Other assets like datasets and Databricks Solution Accelerators are not supported.",
"explanation": "This answer is incorrect because it fails to mention that datasets and Databricks Solution Accelerators can also be shared and accessed on Databricks Marketplace, alongside machine learning models and Databricks notebooks.",
"source": [
"https://docs.databricks.com/en/marketplace/index.html",
"https://docs.databricks.com/en/marketplace/get-started-provider.html"
]
},
{
"incorrect_answer": "On Databricks Marketplace, only machine learning models and Databricks notebooks can be shared and accessed. Other assets like datasets and Databricks Solution Accelerators are not supported.",
"explanation": "This information is incorrect because the Databricks Marketplace actually supports sharing and access to datasets, Databricks notebooks, Databricks Solution Accelerators, and machine learning models. The incorrect answer stems from a misunderstanding that only machine learning models and notebooks can be shared and accessed.",
"source": [
"https://docs.databricks.com/en/marketplace/index.html",
"https://docs.databricks.com/en/marketplace/get-started-provider.html"
]
},
{
"incorrect_answer": "On Databricks Marketplace, users can only share and access pre-configured Databricks clusters and SQL endpoints for data processing tasks.",
"explanation": "The provided context mentions Databricks Marketplace as a platform for sharing data products, but it does not explicitly state that datasets, Databricks notebooks, Databricks Solution Accelerators, and machine learning models can be shared and accessed. It mentions Delta Sharing for secure data sharing, but it does not specifically mention Databricks clusters or SQL endpoints.",
"source": [
"https://docs.databricks.com/en/marketplace/index.html",
"https://docs.databricks.com/en/marketplace/get-started-provider.html"
]
}
]
}This output can be directly used to power a front end UI. If you want to check out what that could look like, take our Databricks themed quiz that was generated with this technique!

Retrieval augmented generation with LLMs is a powerful paradigm for knowledge synthesis tasks. As we've seen in this post, by combining:
We can produce complex artifacts like multiple choice quizzes with robust and maintainable pipelines. While not shown here, other key components of a production RAG system include human feedback loops to continually refine the prompts and fine-tune the models, as well as monitoring systems to evaluate the quality of the generated outputs over time.
The Databricks Lakehouse Platform provides the key building blocks to implement RAG workflows at scale, including:
RAG is still a rapidly evolving space and active area of research, but the potential for enhancing and scaling knowledge work is immense. We're excited to continue partnering with organizations to explore novel RAG applications - if you're interested in learning more, please reach out!
Read more about the latest and greatest work Rearc has been up to.
LLM applications have a semi-infinite attack surface, and they are notoriously hard to secure without breaking the user experience.

Recently, articles surrounding the supposed dangers of an open source abliteration tool called Heretic, along with legal notice being served to its creator, have inspired me to speak out for two reasons.
A step-by-step guide to deploying a Databricks workspace with Private Service Connect (PSC) on GCP and common pitfalls to avoid.

A deep dive into Databricks Foreign Catalogs for Glue Iceberg table access
Tell us more about your custom needs.
We’ll get back to you, really fast
We will evaluate your query and respond within 2 business days.
Kick-off meeting
We will schedule a quick meeting to further understand your use case and start working toward a solution together!