
Red Agent Swarms for Testing Customer-Facing AI Agents
LLM applications have a semi-infinite attack surface, and they are notoriously hard to secure without breaking the user experience.
AI
LLM
AI Safety

In the intricate world of database management, Change Data Capture (CDC) shines as a reliable tool for tracking and logging changes in datasets. Whether it's happening right away or pretty quickly, CDC keeps an eye on data modifications, helping applications react promptly.
Essentially, CDC ensures that data is always up-to-date, which is key for making smart decisions. But it's not just about watching changes; CDC also ensures that data remains consistent across different systems. This means that no matter where your data travels, it stays reliable and accurate.
For tasks like combining data from various sources or analyzing it efficiently, CDC is a lifesaver. It simplifies the process, making it easier for organizations to make the most of their data. In a nutshell, CDC is like a trusty sidekick in the world of data management, always there to ensure smooth operations and informed decision-making.
Change Data Capture (CDC) is a fundamental process in database management, facilitating the transmission of data alterations from an Online Transaction Processing (OLTP) database to a multitude of destination systems such as cache indexes, data lakes, warehouses, or other relational databases. These alterations encompass insertions, updates, or deletions within the source database, and CDC ensures the seamless replication of these changes across the destination systems in real-time.
While the primary source systems for CDC are typically relational databases, it's important to note that this principle is adaptable to any source system, including NoSQL databases and flat file storage. This adaptability underscores the versatility and applicability of CDC in diverse data environments.
A typical CDC workflow comprises a source database, a CDC framework, and one or more destination systems. This structured workflow ensures the efficient and accurate transmission of data changes across the data ecosystem.
The architecture of CDC relies on leveraging the inherent properties of the source database or employing an active data extraction method to facilitate uninterrupted data flow between the source and destination systems. This architecture ensures the reliability and integrity of data replication processes.
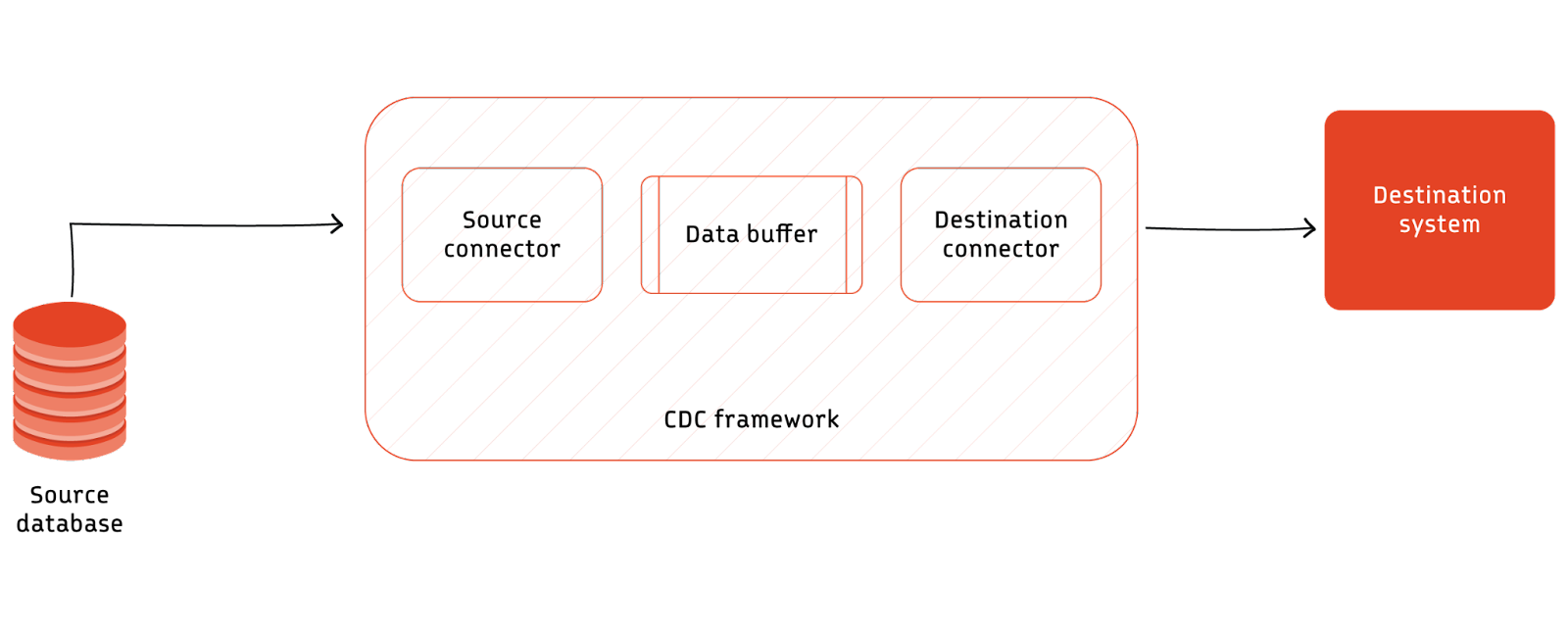
Implementing CDC often necessitates decoupling the source and destination systems to accommodate the varying rates of change in the source database. This decoupling mechanism enables flexible and scalable data replication, ensuring that the destination systems can effectively keep pace with the dynamic nature of the source data.
In essence, CDC serves as a linchpin in modern data management strategies, enabling organizations to efficiently synchronize data across disparate systems and leverage real-time insights for informed decision-making.
CDC allows businesses to monitor all database changes in real-time, which is essential for those handling big volumes of data. Making decisions quickly is made easier by this instant access to data.
By keeping thorough records of all data modifications, CDC helps companies comply with regulatory standards. This guarantees accountability and openness in data management procedures.
For jobs involving data integration, analytics, and warehousing, CDC is essential. Businesses would find it difficult to effectively handle and analyze the steady stream of data changes without CDC.
CDC assists in quickly identifying and fixing problems with data quality by recording all database modifications. This proactive strategy improves the overall dependability and correctness of the data.
By lowering data latency, CDC gives decision-makers access to the most recent information. Businesses are able to react swiftly to changes in the market and take well-informed decisions because of this agility.
By streamlining data management procedures, CDC implementation lowers human labour requirements and boosts output. It guarantees that companies may concentrate on things that provide value instead of managing and collecting data.
The following are the most common methods for implementing Change Data Capture (CDC) in a data pipeline.
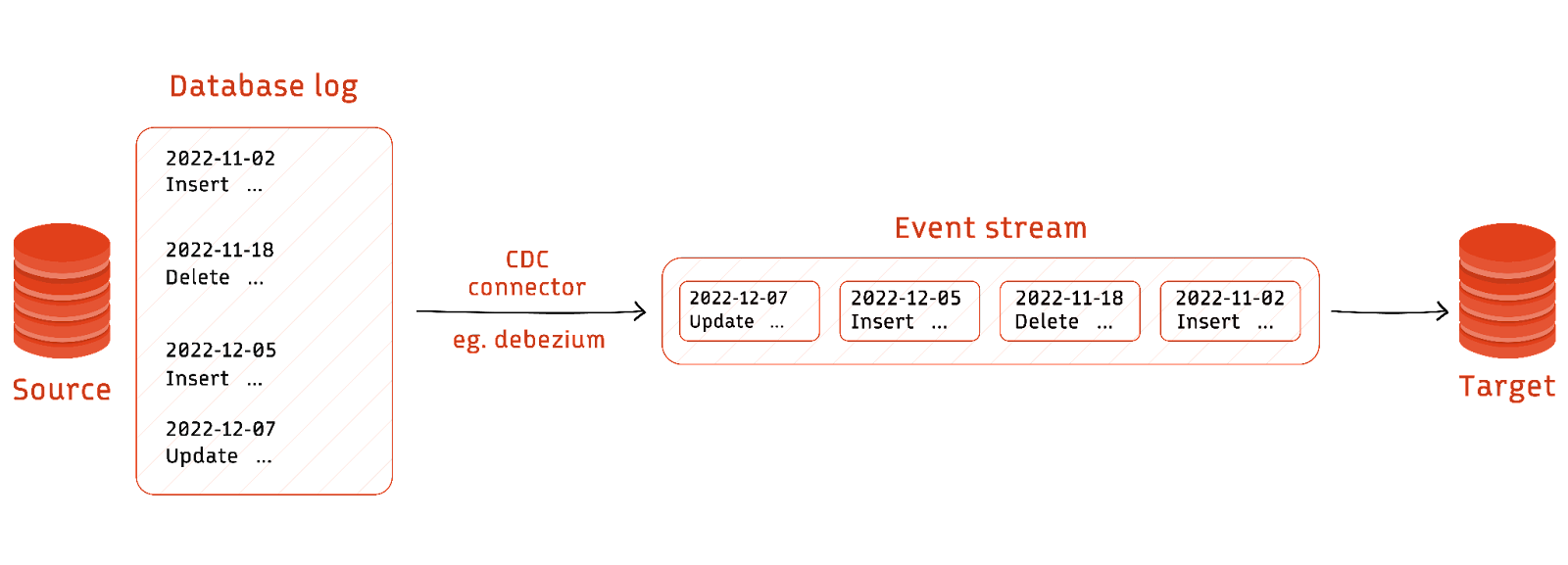
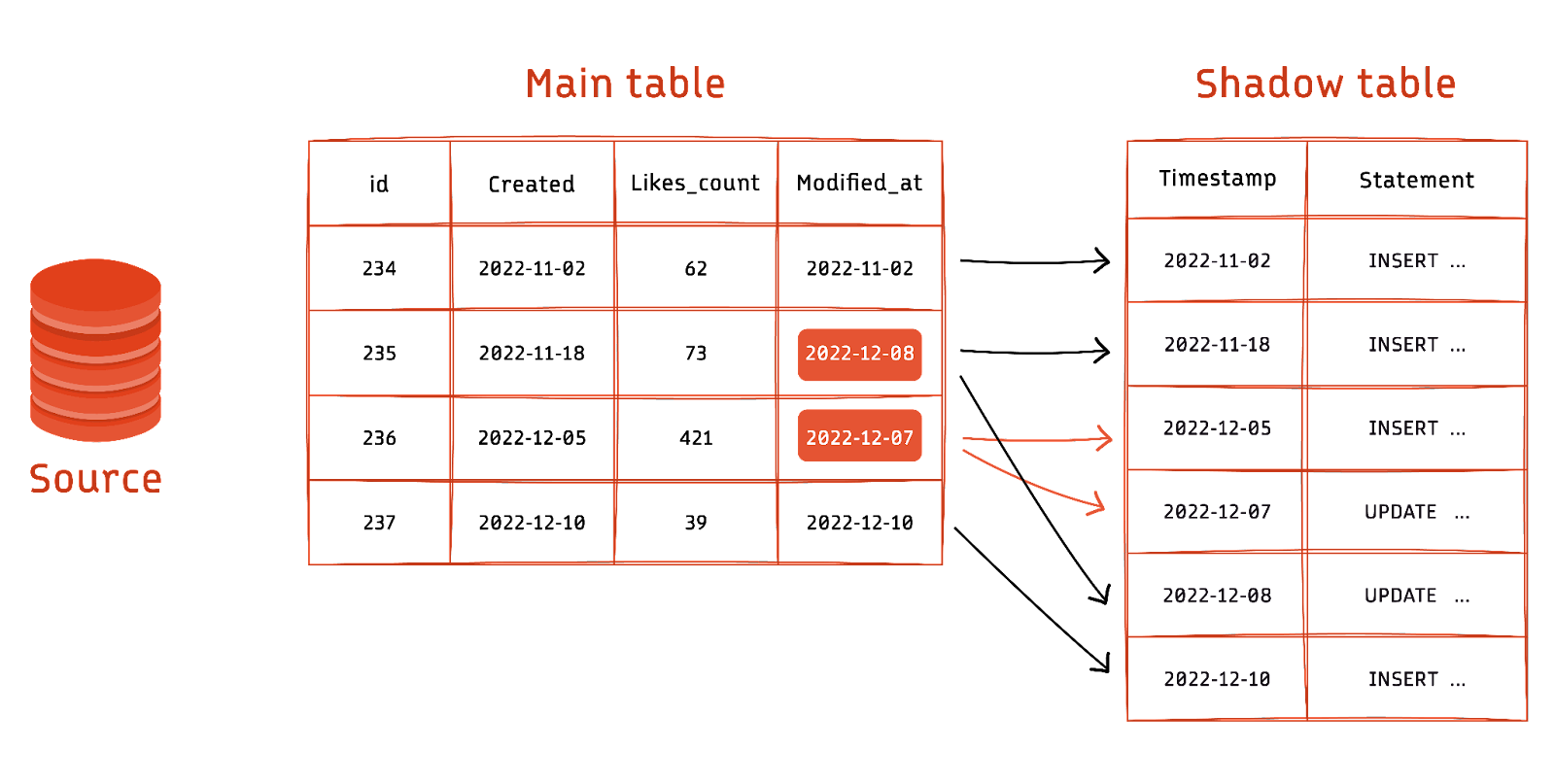
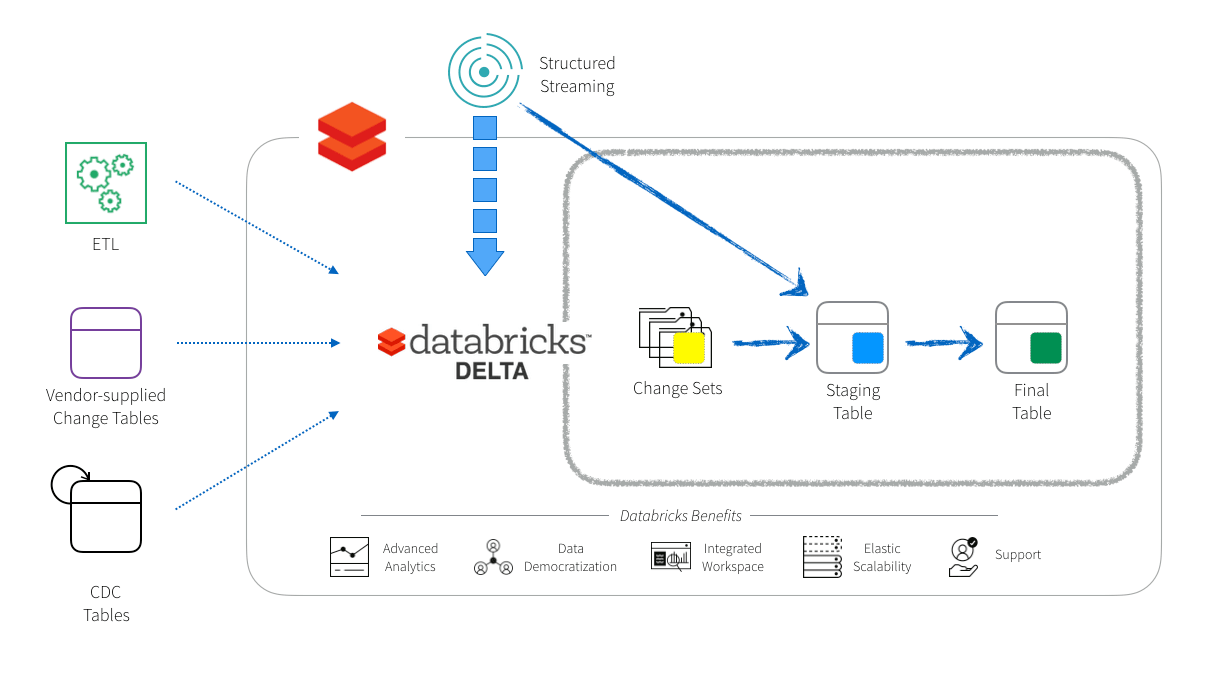
Databricks commonly encounters customers seeking to perform Change Data Capture (CDC) from various sources into Delta tables. These sources range from on-premises to cloud-based, including transactional stores and data warehouses.
The unifying factor is the generation of change sets, facilitated through ETL tools like Oracle GoldenGate or Informatica PowerExchange, vendor-supplied change tables (e.g., Oracle Change Data Capture), or user-maintained tables with triggers. To address this, Databricks offers a reference architecture leveraging Delta features for efficient CDC implementation, drawing from extensive experience across public and private sector deployments.
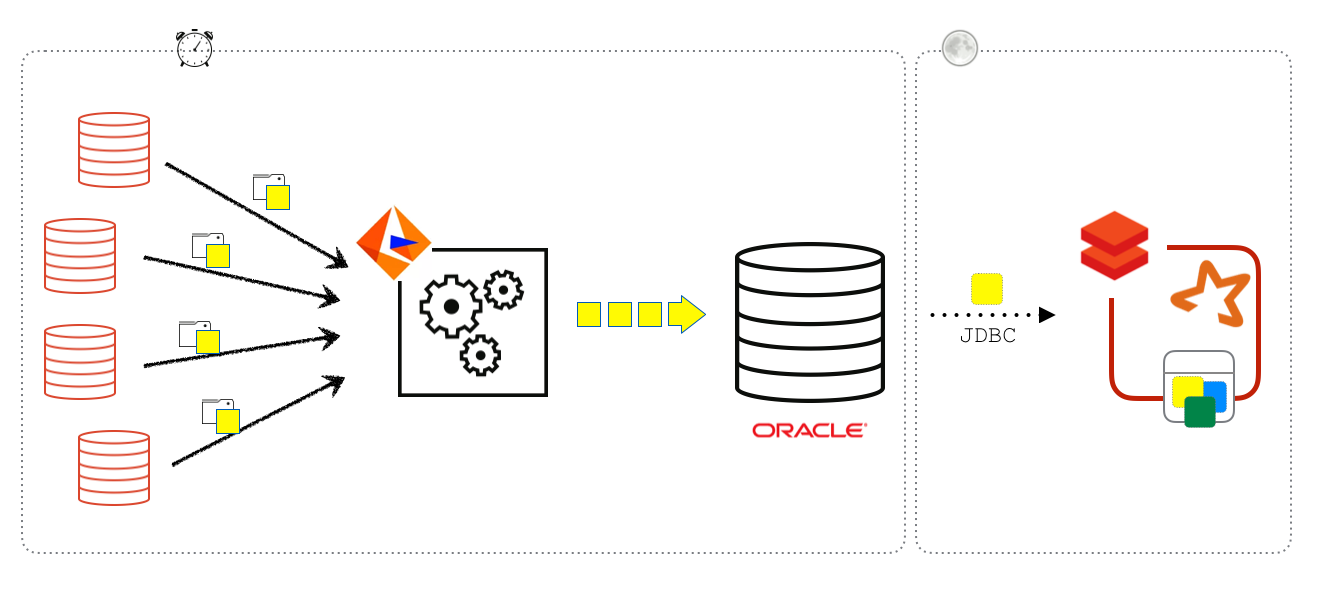
Before the advent of Databricks Delta, customers commonly established Change Data Capture (CDC) pipelines using tools such as Informatica, with Oracle acting as an intermediary before the data reached Databricks.
In this setup, Informatica was responsible for consolidating change sets from various sources into an Oracle data warehouse. Databricks jobs would then fetch these change sets from Oracle, usually once a day via JDBC, and proceed to update tables within Databricks. However, this method posed several challenges.
Primarily, it imposed strain on the Oracle instance due to the additional workload, leading to constraints on the scheduling of Extract, Transform, Load (ETL) jobs. Moreover, the refresh rates were restricted to nightly updates owing to concurrency issues associated with traditional Parquet tables.
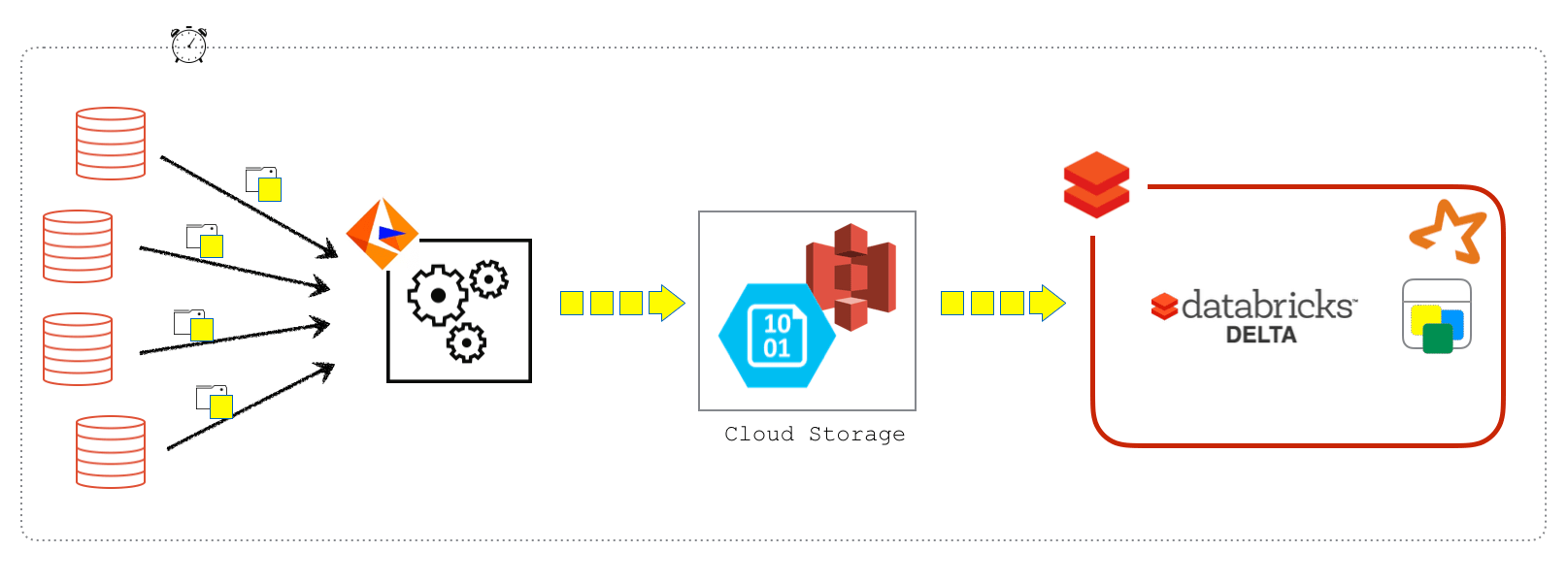
With Databricks Delta, the CDC pipeline is more efficient, enabling more frequent updates. Change sets from sources like Informatica are directly written to S3. Databricks jobs can then run more frequently to process these changes and update Delta tables. This process can also be adapted to read CDC records from Kafka.
The pipeline involves maintaining a staging table to accumulate updates and a final table for the current snapshot. Each refresh period, a Spark job performs two main tasks: inserting new changes into the staging table and overwriting the final table with the latest data from the staging table.
This approach supports different update handling strategies, resembling SCD Type 2 for the staging table and SCD Type 1 for the final table. This streamlined process was successfully implemented for a customer's ETL pipeline, resulting in efficient updates to Delta tables.
The introduction of the Apply Changes API in Delta Live Tables marks a significant advancement in simplifying Change Data Capture (CDC) processes. This API streamlines CDC by automatically managing out-of-sequence records, thereby obviating the need for intricate logic. It supplants the commonly used "merge into" statement for CDC processing on Databricks, offering a more intuitive and efficient approach. With its robust functionality, the Apply Changes API ensures accurate processing of CDC records while supporting the updating of tables with both SCD type 1 and type 2 configurations. SCD type 1 updates directly overwrite existing records without retaining historical data, whereas SCD type 2 preserves historical records, either for all updates or selectively for specified columns, empowering users with enhanced flexibility and precision in data management.
To implement Change Data Capture (CDC) with Delta Live Tables, follow these steps for efficient and accurate data tracking and processing.
To perform CDC processing, do the following:
In conclusion, Change Data Capture (CDC) is a critical process in modern data engineering, enabling organizations to track and record data modifications in real-time. With the evolution of technologies like Databricks Delta and Delta Live Tables, implementing CDC has become more streamlined and efficient, empowering businesses to maintain data consistency across systems and make informed decisions based on up-to-date information. By adhering to best practices and leveraging advanced features such as the Apply Changes API, organizations can simplify CDC implementation and enhance their data management practices. As the volume and complexity of data continue to grow, CDC remains an essential tool for organizations seeking to harness the full potential of their data assets and drive business success.
Read more about the latest and greatest work Rearc has been up to.
LLM applications have a semi-infinite attack surface, and they are notoriously hard to secure without breaking the user experience.

Recently, articles surrounding the supposed dangers of an open source abliteration tool called Heretic, along with legal notice being served to its creator, have inspired me to speak out for two reasons.
A step-by-step guide to deploying a Databricks workspace with Private Service Connect (PSC) on GCP and common pitfalls to avoid.

A deep dive into Databricks Foreign Catalogs for Glue Iceberg table access
Tell us more about your custom needs.
We’ll get back to you, really fast
We will evaluate your query and respond within 2 business days.
Kick-off meeting
We will schedule a quick meeting to further understand your use case and start working toward a solution together!