
Red Agent Swarms for Testing Customer-Facing AI Agents
LLM applications have a semi-infinite attack surface, and they are notoriously hard to secure without breaking the user experience.
AI
LLM
AI Safety

A picture is worth a thousand words
-Fred R. Barnard
In the rapidly changing world of LLMs, chatbots, and RAGs (Retrieval-Augmented Generation), most of the focus has been on plain text data. However, a wealth of information is available only in image form:
In many cases, images provide novel information that is not provided clearly in any surrounding context.
In this article, we'll discuss various ways to integrate multimodal information into a RAG chatbot, and then demonstrate a structurally simple but extremely powerful approach powered by Databricks and OpenAI's GPT-4.
There are a variety of ways of interacting with image data using modern AI:
To function in a scalable fashion, we most of all need images to be indexable, and preferably we need some control over how that indexing occurs. While multimodal embeddings deliver on the first need and can provide a semantic index for an image, those embeddings don't tell us why an image means what it means. We need to rely on either presenting the image to the end-user without comment or on having a multimodal LLM later in our pipeline to extract necessary information from the image.
Image querying is incredibly powerful, but does not provide a way to discover relevant images in a big data context. It works best once you already have a small number of images you know are relevant to the user's needs.
By going down the route of captioning or describing images, we gain several powerful features:
A complete RAG system is a combination of several moving parts. In order to make images retrievable by the complete RAG system, we must ensure that our image descriptions fit into our data ingestion pipeline that drives our vector store.

For enterprise use cases, this data ingestion pipeline must be scalable and robust. As such, this article is going to focus on how to implement this step using Spark, powered by Databricks. We'll rely on OpenAI's GPT-4 to provide the actual descriptions, which is itself a scalable, enterprise-grade service.
For this demonstration, we're going to use a simple Wikipedia corpus.
This dataset is five Wikipedia pages, chunked up into sections (text) and images. The result is ~150 chunks, ~50 of which are images. Each image is represented by the URL to that image as a PNG or JPG. For each chunk, we record which Wikipedia page it belongs to and also an identifier for that chunk (either the section header or the image name).
Our goal is to transform all the image chunks into text. This will let us take the entire textual content column and map it into a vector database for querying later.
We'll start by loading this dataset into Pyspark:
# We use Pandas here to load the CSV only because it's simpler and works at this scale.
# In production, use Spark to load your data, and store your data in Parquet or some
# other efficient tabular storage.
import pandas as pd
df = pd.read_csv('s3://rearc-data-public/demos/wikipedia_silver.csv')
(spark.createDataFrame(df)
.write
.option('overwriteSchema', 'true')
.option('delta.enableChangeDataFeed', 'true')
.mode('overwrite')
.saveAsTable(raw_data_table_path)
)We need to write a custom function to submit our image to GPT-4 for description.
As of the time of writing, this requires using the preview model gpt-4-vision-preview.
This may change in the future.
from openai import OpenAI
def describe_image(uri):
client = OpenAI(api_key=api_key)
response = client.chat.completions.create(
model="gpt-4-vision-preview",
messages=[
{
"role": "user",
"content": [
{"type": "text", "text": "Describe the image in detail"},
{
"type": "image_url",
"image_url": {
"url": uri,
},
},
],
}
],
# We can always shorten later, but for initial description, let's get as much as we can
max_tokens=4096,
)
return response.choices[-1].message.contentOf note, we can prompt the model however we please, and provide it as much or as little space to answer us. This gives us a great deal of flexibility depending on what we know about our images and what information we expect to need to locate our images later. For example, if we have a caption or other context for the image, we can provide that alongside our prompt to get a more accurate description.
We then wrap this as a UDF so we can parallelize it across our Spark cluster.
from pyspark.sql.functions import pandas_udf
import pandas as pd
@pandas_udf("string")
def describe_image_udf(urls: pd.Series) -> pd.Series:
"""Given strings of image URIs (can be base64 data URIs or public URLs), return GPT-4 descriptions of those images.
Note that, while Spark may parallelize these calls, OpenAI will rate limit your calls globally. The main limit likely to
come up is Tokens Per Minute. If this may be an issue, you can enable the retry logic below, which will allow the UDF
to retry the OpenAI API calls
"""
def describe_image(...):
...
return pd.Series([
describe_image(url)
for url in urls
])With our data at hand and our description function ready to go, we can clean up our data.
For textual rows, we'll simply truncate the data. This text is both what will be indexed and also, when the chunk is retrieved at query time, what we'll add to our LLM's context to answer the user's question. Given token limits on both of these processes, it's important to make sure that our text chunks are all of reasonable length. In a separate post, we'll show how to use LLMs to shorten overly long data in more useful ways.
For image rows, we'll use our description function to convert the image URL into a textual description of that image.
Once finished, we'll save our data.
from pyspark.sql.functions import col, lit, when, concat
raw_data = spark.table(raw_data_table_path)
cleaned_data = raw_data.withColumn(
"content",
when(col("type") == "image", describe_image_udf(col("content")))
.otherwise(col("content").substr(0, 10000)) # Vector index caps out at 32k, but also we risk bloating our context window
).cache()
# Need a primary key for each row
cleaned_data = cleaned_data.withColumn("pk", concat(col("url"), lit(":"), col("title")))
(cleaned_data.write
.format("delta")
.option("delta.enableChangeDataFeed", "true")
.mode("overwrite")
.saveAsTable(source_data_table_path)
)Note that the image descriptions are, by default, non-deterministic: if you describe the same image multiple times, you may get different results each time. There are ways to limit or eliminate this variance if needed. Also, in a production use case, the cost (both time and service costs) of describing images may be such that it's worthwhile to cache these descriptions to prevent duplicate effort. This will be discussed in a separate post.
The results of this code are available here. Let's take a look at some of them.
This table can now be hooked up to a Databricks Vector Search Index, which will automatically update and generate searchable vectors for each of our text blobs.
from databricks.vector_search.client import VectorSearchClient
vsc = VectorSearchClient(disable_notice=True)
index = vsc.create_delta_sync_index(
endpoint_name=endpoint_model_name,
source_table_name=source_data_table_path,
index_name=vs_index_table_path,
pipeline_type='TRIGGERED',
primary_key="pk",
embedding_source_column="content",
embedding_model_endpoint_name=embedding_model_endpoint
)Further details about building a RAG on top of this vector index can be found in Databricks' official documentation.
The point of describing and embedding images is that there may be information available in those images that is not available in the surrounding text. This dataset provides some contrived examples, but realistic cases abound in real situations (technical diagrams, flowcharts, etc.).
Here, for example, is a flowchart provided on the Wikipedia page about Diagrams in general:
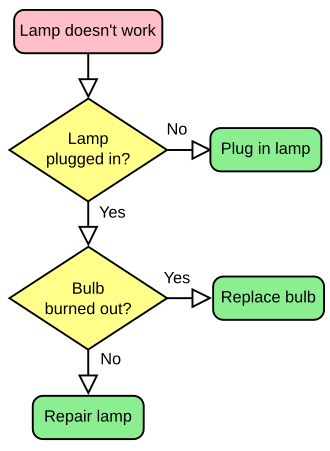
This is the description generated for this image:
The image shows a flowchart that outlines a troubleshooting process for a lamp that doesn't work. The flowchart is created with different shapes for each step, connected by arrows that indicate the flow of the process.
At the top, in a pink rectangle with rounded corners, the process begins with the statement "Lamp doesn't work". An arrow points downwards to the first decision point, represented by a yellow diamond shape, asking the question "Lamp plugged in?". Two arrows emerge from this decision point:
1. If the lamp is not plugged in, an arrow points to the right, leading to a green rectangle instructing to "Plug in lamp".
2. If the lamp is plugged in, an arrow points downward to another decision point, also in a yellow diamond shape, asking "Bulb burned out?".
Similarly, from this second decision point, two arrows direct the flow:
1. If the bulb is burned out, an arrow points to the right, leading to another green rectangle with the instruction "Replace bulb".
2. If the bulb is not burned out, the final step is shown with a downwards arrow leading to a dark green rectangle with the action "Repair lamp".
The flowchart is a simple, logical sequence for diagnosing and fixing a common problem with a lamp.Note that this description doesn't merely describe the visuals of the image, but actually encapsulates its knowledge, including what to do in each circumstance. This knowledge is not provided in the original Wikipedia page, which has nothing to do with lamps, and is thus novel, practical knowledge the RAG can draw on.
Another example is the following sentence diagram:

The description for this image includes the following:
The image shows a simple tree diagram of a sentence, commonly used in linguistics to represent the syntax structure of a sentence. At the top, there's the label 'S', indicating the sentence as a whole. This branches off into two: 'N' for noun and 'VP' for verb phrase on the right.... The sentence translates into English as "Janek sees Marysia." The diagram breaks down the sentence into its grammatical components.
In this case, GPT-4 recognizes that the image is a diagram, what it represents, that the words are Polish, what the equivalent English is, and even how to undo the grammatical parsing into the original sentence structure.
While individual results may vary, these examples demonstrate that GPT-4 is capable of providing useful descriptions to non-trivial images, providing results that add real value to a RAG pipeline.
In this article, we have demonstrated how to integrate images into any RAG pipeline to allow the final chat system and LLM to leverage knowledge available visually. We showed a few random examples that clearly demonstrated useful knowledge being extracted from these images without reliance on any surrounding textual information.
Rearc provides services to satisfy bespoke LLM, AI, and MLOps requirements in complicated enterprise contexts like financial services and healthcare. We bring a strong Cloud and DevOps background, so you can trust that your solutions are scalable and maintainable. If you have any enterprise AI requirements you need help with, just reach out to us at ai@rearc.io for consultation.
Read more about the latest and greatest work Rearc has been up to.
LLM applications have a semi-infinite attack surface, and they are notoriously hard to secure without breaking the user experience.

Recently, articles surrounding the supposed dangers of an open source abliteration tool called Heretic, along with legal notice being served to its creator, have inspired me to speak out for two reasons.
A step-by-step guide to deploying a Databricks workspace with Private Service Connect (PSC) on GCP and common pitfalls to avoid.

A deep dive into Databricks Foreign Catalogs for Glue Iceberg table access
Tell us more about your custom needs.
We’ll get back to you, really fast
We will evaluate your query and respond within 2 business days.
Kick-off meeting
We will schedule a quick meeting to further understand your use case and start working toward a solution together!