
Red Agent Swarms for Testing Customer-Facing AI Agents
LLM applications have a semi-infinite attack surface, and they are notoriously hard to secure without breaking the user experience.
AI
LLM
AI Safety

Hi, I am Michael Derrico, and I am currently entering my senior year at Fordham University's Gabelli School of Business, where I am pursuing a major in Finance with a concentration in Financial Technology. This post dives into a project I designed and worked on through Rearc's guidance and support, which sharpened my data skills and demonstrates how data analytics, when thoughtfully designed, doesn’t have to be complex to be effective.
Understanding public sentiment around brands, products, and events in real-time has traditionally required specialized data teams, complex infrastructure, and weeks of development time. This project breaks down those barriers by demonstrating how platforms like Databricks, combined with AI tools, can transform anyone into a capable data analyst. What once demanded deep technical expertise-scraping multiple social media platforms, applying machine learning models, and generating executive summaries–now becomes as simple as typing a search term and clicking run.
By building a sentiment analysis pipeline that ingests data from X/Twitter, Reddit, and news sources, this solution showcases the true power of democratized analytics. The heavy lifting happens behind the scenes through Databricks’ unified workspace, Hugging Face’s pre-trained models, and OpenAI’s natural language generation capabilities, while the end user experience remains remarkably simple: enter a topic/brand of interest and receive comprehensive, AI-powered insights within minutes. This represents a fundamental shift in how organizations can approach data-driven decision making–moving from exclusive, expert-dependent processes to inclusive, self-service analytics that empower every team member to extract meaningful insights from complex, real-time data streams.
Goal: Build a scalable, repeatable workflow that can...
What the workflow must deliver:
ai_analyze_sentiment and built-in connectors with Hugging Face machine learning models provide accurate sentiment analysis.Having established why Databricks provides the ideal foundation for this project, let's examine how the sentiment tracking system actually works. The following workflow breakdown demonstrates how raw social media data transforms into actionable business insights.
All three are retrieved within a Databricks notebook where Delta Lake stores the data in a consistent, query-friendly structure.
ai_analyze_sentiment provides a sentiment label to each data point.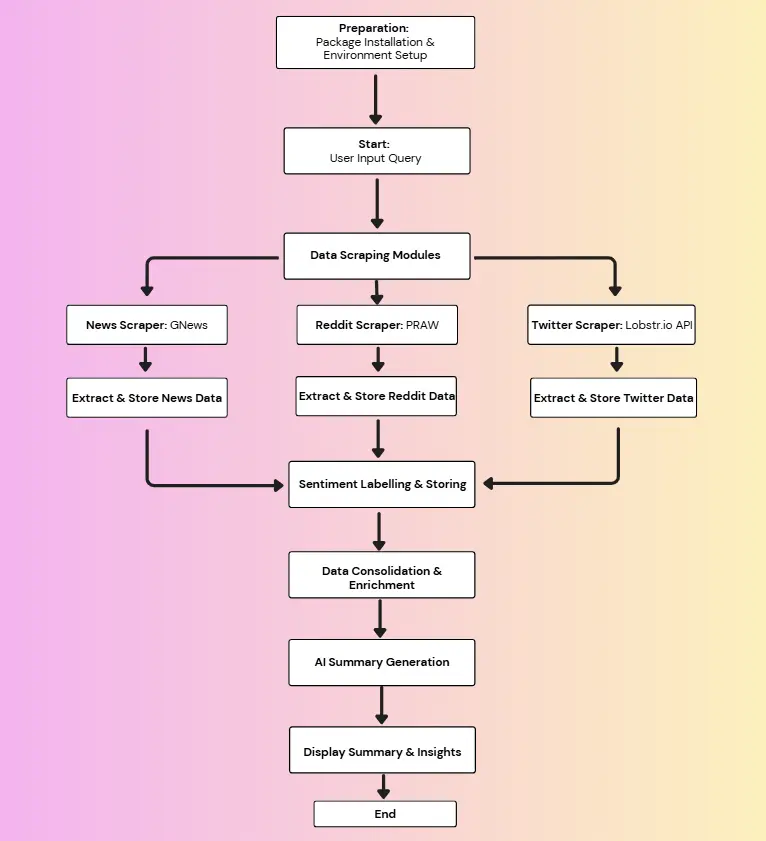
My approach prioritized simplicity and accessibility over technical complexity, proving that sophisticated analytics can be intuitive for any user. Rather than building custom infrastructure for each data source, I leveraged built in and connected Databricks functions and tools to handle the complexity. A part of that complexity came from issues that would arise if there were any duplicates collected in the scraping process, which led to my decision to use the data point’s URL as a primary key when loading in new data. URL-based deduplication through Delta Lake’s MERGE operation means users never worry about data quality issues.
When first developing the code and idea as a whole, I realized the NLTK(natural language tool kit) python based, sentiment analysis tool I was using was not all too consistent in the scores it provided, but in general was just not accurate, so I knew if I wanted an accurate, numerical, sentiment analysis values, I would need to use a LLM(large language model). In the end, I decided on using a pre-trained sentiment model from Hugging Face, rather than the traditional way of building custom algorithms on a large enough dataset. Choosing the pre-trained model from Hugging Face not only saved me time in development, but further demonstrates how democratizing AI puts enterprise-grade material learning within reach of business analysts who have never written Python code. Finally, the schema standardization across Reddit, X/Twitter, and news sources happens automatically, while also saving the original forms, so users focus on data insights rather than wrestling with data formatting. This architectural philosophy–hiding complexity while preserving power–exemplifies how modern data platforms transform analytics from a specialized discipline into an everyday business capability.
Future enhancements will further demonstrate how democratized analytics evolve with minimal technical overhead, making advanced capabilities accessible to even broader audiences. Implementing automated weekly runs allows the data and dashboards to stay up to date on public sentiment. Automated weekly runs could be implemented through setting up a schedule for the notebooks to run using a constant query through Databricks’ point-and-click interface, allowing marketing teams or product managers to set up brand tracking without data engineer involvement. A further enhancement that can be performed from there is setting up an alert and AI summary to notify the user when there is a dramatic shift in the sentiment. Finally, with more technical prowess, you can expand the data sources to platforms like YouTube or specified consumer review sites (like Consumer Reports, J.D. Power, and CNET) to perform more sophisticated product/brand sentiment analysis rather than general public sentiment. These incremental improvements underscore the project’s core thesis: as data tools become more intuitive and AI-assisted, the gap between having a question and finding an answer continues to shrink, ultimately putting sophisticated analytics capabilities into the hands of anyone curious enough to ask.
Read more about the latest and greatest work Rearc has been up to.
LLM applications have a semi-infinite attack surface, and they are notoriously hard to secure without breaking the user experience.

Recently, articles surrounding the supposed dangers of an open source abliteration tool called Heretic, along with legal notice being served to its creator, have inspired me to speak out for two reasons.
A step-by-step guide to deploying a Databricks workspace with Private Service Connect (PSC) on GCP and common pitfalls to avoid.

A deep dive into Databricks Foreign Catalogs for Glue Iceberg table access
Tell us more about your custom needs.
We’ll get back to you, really fast
We will evaluate your query and respond within 2 business days.
Kick-off meeting
We will schedule a quick meeting to further understand your use case and start working toward a solution together!