
Red Agent Swarms for Testing Customer-Facing AI Agents
LLM applications have a semi-infinite attack surface, and they are notoriously hard to secure without breaking the user experience.
AI
LLM
AI Safety

Hello, my name is Garv Sen. I recently graduated high school and I will be starting school at the University of Michigan Ross Business School this upcoming fall. I was a Rearc summer intern from June to August, 2025.
Hiring is moving too slowly. We have new projects and open roles that need to be filled fast, but the hiring process is inefficient. A lot of the slowdown is happening at the sourcing and assessment stages. Many applicants are not responsive, and even those who progress all the way to final interviews often get rejected because they are not technical enough or not a cultural fit.
In the beginning, we tried to track everything manually. Applicant data was entered into a spreadsheet, then exported into Rippling (a human resources workflow management system) to run basic analytics. This was unsustainable. Manual entry took too long and was prone to errors. The data was never fully up to date, and we spent more time managing the spreadsheet than actually making decisions from the data.
Now, the process is far more efficient. Most applicant information is automatically stored in Rippling as soon as a profile is created. With some support, I built out automated reports directly in Rippling that track rejection reasons and hiring stage progress, grouped by location and recruiting agency. The reports update daily, and because they are connected directly to Rippling, there is no need for constant exports or manual updates. The reports are all accessible on the Talent Pipeline Analysis custom app.
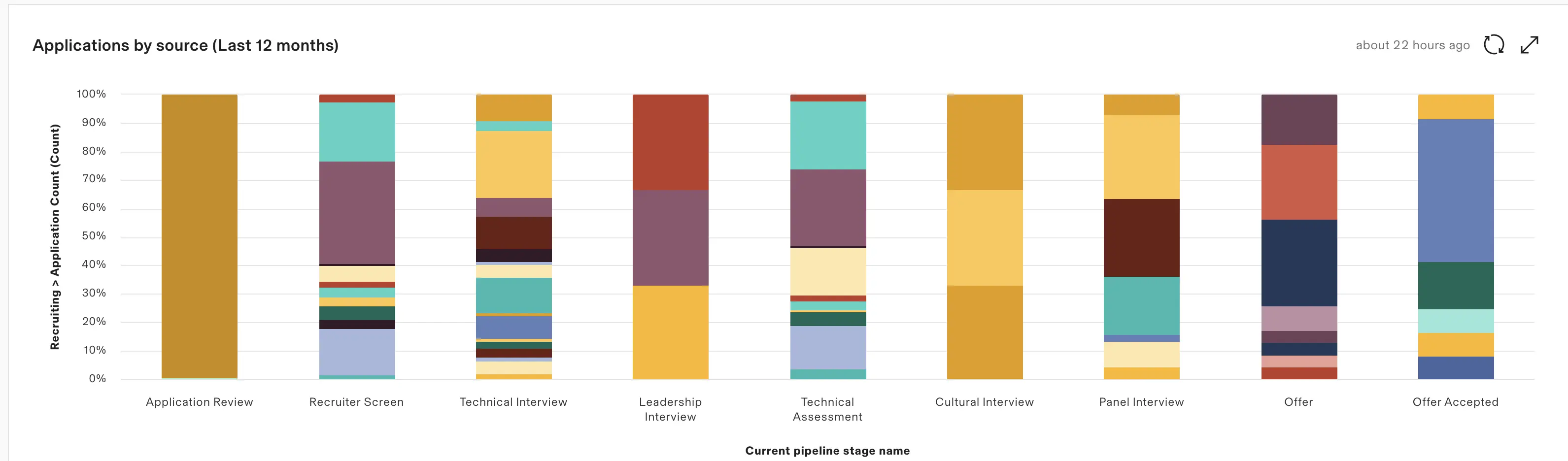
One of the biggest advantages of automating the reports is being able to evaluate our recruiting agencies more effectively. We can now track how many candidates each agency submits and how far those candidates make it in the process. If an agency is sending a lot of applicants who get rejected early on, it usually means they are focused on hitting quotas instead of finding good fits.
The reports also help us understand rejection trends by source. We can break rejections down by location or by agency and start to see patterns. For example, if a certain agency's candidates keep getting rejected for technical skill, or if applicants from one job requisition location rarely pass the culture fit screen. That kind of insight makes it easier to adjust our sourcing strategy and have more informed conversations with recruiters.
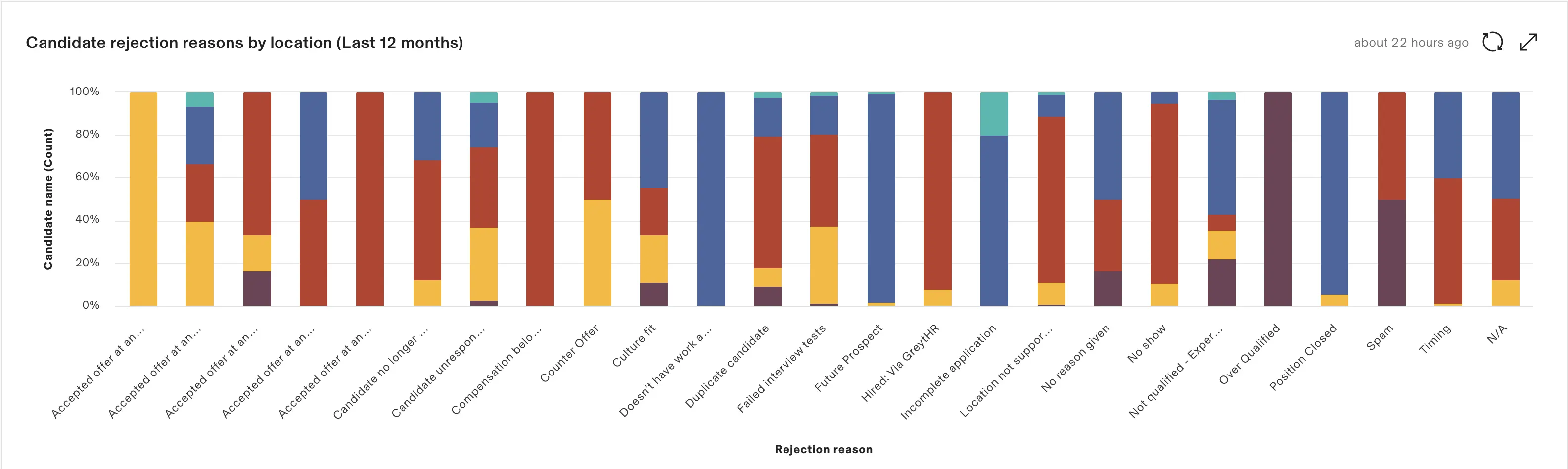
During hiring surges, the reports can be used to prioritize candidates that are statistically more probable to get further in the hiring process. If Agency X gives us 50% of unresponsive candidates, and we get 100 applications on a day, 50 from Agency X and 50 from Agency Y, we know we should start by reviewing the candidates from Agency Y.
As an intern, I did not have access to most of the data I needed for these reports. I got help from my higher-ups and people in HR to create reports with the correct data. This lack of access also prevented me from exploring capabilities for the project when I started. I also had to learn how to make an app and reports on the Rippling interface. Additionally, I had never used RQL (Rippling Query Language), which is the language used to make custom fields. I took courses on Rippling University to help with all of this.
This app should be able to expand its scope of helping HR past the end of my internship. I developed a Python program that uses OpenAI’s API to analyze resumes from a Google Sheet. It extracts applicant name and country, summarizes the resume based on strengths and weaknesses, returns a candidate score, and marks booleans true/false for Kubernetes and OpenAI experience. These are then automatically placed back into the Google Sheet in corresponding columns using Google Sheets API. Rippling's automatic applicant tracking system can be connected with a public API via a workflow. The resumes files that are datapoints in each applicant can be analyzed with the API call.
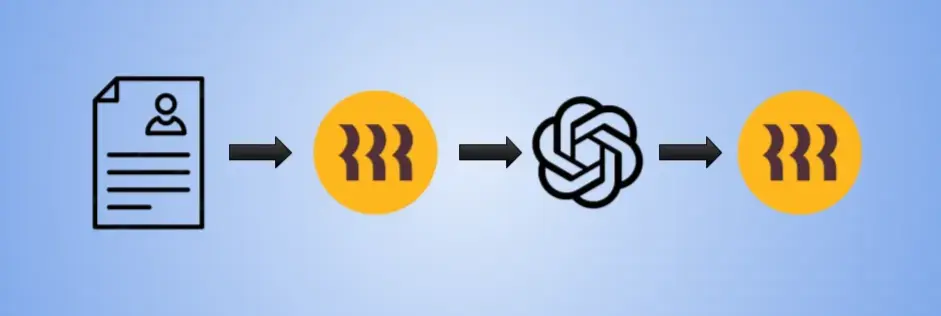
An obvious capability is creating reports based on other variables. These can be sorted by interviewers, school degree, job sites, etc. This is the simplest way of increasing the value of the custom app, and it should not be overlooked. There are tons of datapoints on Rippling that are waiting to be used. In terms of using recruiting data outside of Rippling, there is also a functionality on Rippling to download and export any reports. This can be used to analyze the information on a more data-centric platform, or even with AI.
Cristina Orlando and Michael Kaufman - App and Report Building, Oversight
Anthony Gargan - Data Entry, Ideas
Rahul Sen - User Testing
Read more about the latest and greatest work Rearc has been up to.
LLM applications have a semi-infinite attack surface, and they are notoriously hard to secure without breaking the user experience.

Recently, articles surrounding the supposed dangers of an open source abliteration tool called Heretic, along with legal notice being served to its creator, have inspired me to speak out for two reasons.
A step-by-step guide to deploying a Databricks workspace with Private Service Connect (PSC) on GCP and common pitfalls to avoid.

A deep dive into Databricks Foreign Catalogs for Glue Iceberg table access
Tell us more about your custom needs.
We’ll get back to you, really fast
We will evaluate your query and respond within 2 business days.
Kick-off meeting
We will schedule a quick meeting to further understand your use case and start working toward a solution together!