
Red Agent Swarms for Testing Customer-Facing AI Agents
LLM applications have a semi-infinite attack surface, and they are notoriously hard to secure without breaking the user experience.
AI
LLM
AI Safety
Hi, I'm Mueez Khan. I'm currently an undergraduate Computer Science student at Rutgers University, and I was a remote summer intern at Rearc from June to September, 2022.
In this article we'll go over various projects and achievements during my internship at Rearc.
![]()
Rearc is a boutique cloud software & services firm with engineers that have years of experience shaping the cloud journey of large scale enterprises. Our engineers are skilled at planning application migrations to the cloud and building cloud-native application environments and patterns for the future. We build strategic partnerships with our enterprise customers to enable long term success in the cloud.
Rearc additionally provides data products on AWS Data Exchange (ADX) and Databricks with customers. Rearc is an Advanced Consulting Partner for the AWS Partner Network and a Databricks Technology Partner.
My main projects during the internship involved working with Rearc's data platform infrastructure.
One of the first tasks I completed was implementing a change that would lower AWS billing costs from the data platform's existing infrastructure.
This data platform has jobs running on compute resources in a private subnet. These jobs may access data from public data sources or S3 buckets.
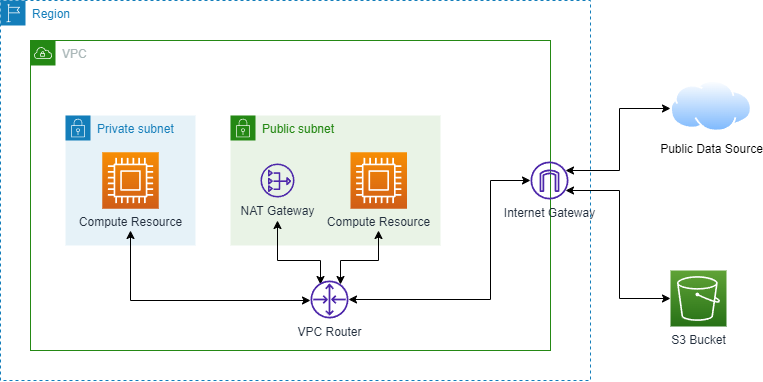
The architecture diagram above shows a sample initial architecture where a compute resource in a private subnet needs to access data sources from the public internet and S3 buckets. To access external data sources from the Internet, a NAT gateway is used. However, there are data processing charges for traffic that uses the NAT gateway.
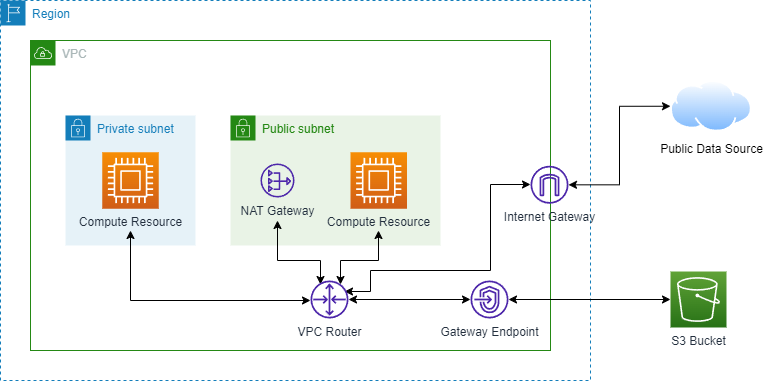
To reduce overall charges with our infrastructure, we are able to implement a VPC gateway endpoint. This endpoint allows our compute resources in the private subnet to access data from S3 buckets without going through a NAT gateway. The architecture still has a NAT gateway in case our compute resources need to access public data sources other than S3. Therefore, I worked on adding a VPC gateway endpoint resource to the data platform's infrastructure.
The data platform is built using AWS Cloud Development Kit (AWS CDK), an infrastructure-as-code (IaC) framework. However, my initial attempt involved creating an endpoint resource using Terraform (another IaC framework) and converting that to AWS CDK code. I started my attempt this way in order to explore whether engineers would be able to write custom Terraform modules and automatically integrate them into the existing AWS CDK infrastructure. I quickly learned that the conversion from Terraform to AWS CDK is not currently supported, and I actually converted my Terraform code to CDK for Terraform (CDKTF) code which is a completely different CDK than AWS CDK, despite the similarity in name.
I implemented the VPC gateway endpoint using AWS CDK and successfully added the VPC gateway endpoint to Rearc's data platform.
Once the VPC gateway endpoint had been added, there was still the need to verify that the changes actually worked.
To this end, I implemented a solution of enabling VPC flow logs which published to CloudWatch logs. With this implementation, we could analyze the IP traffic between the data platform's compute resources and the VPC gateway endpoint to ensure that traffic involving S3 works as expected.
As with the VPC endpoint, I implemented the VPC flow logs using AWS CDK and had them publish to a CloudWatch log group which could be analyzed with CloudWatch Log Insights.
Further details on implementing VPC flow logs using AWS CDK, their benefits, and gathering insights can be found from my first technical publication on Rearc's engineering blog.
Enabling VPC flow logs led to my final main project, which is building a data pipeline. I wanted to build a customizable pipeline to visualize insights from flow log data and use the Databricks Lakehouse Platform for its Databricks Notebook feature.
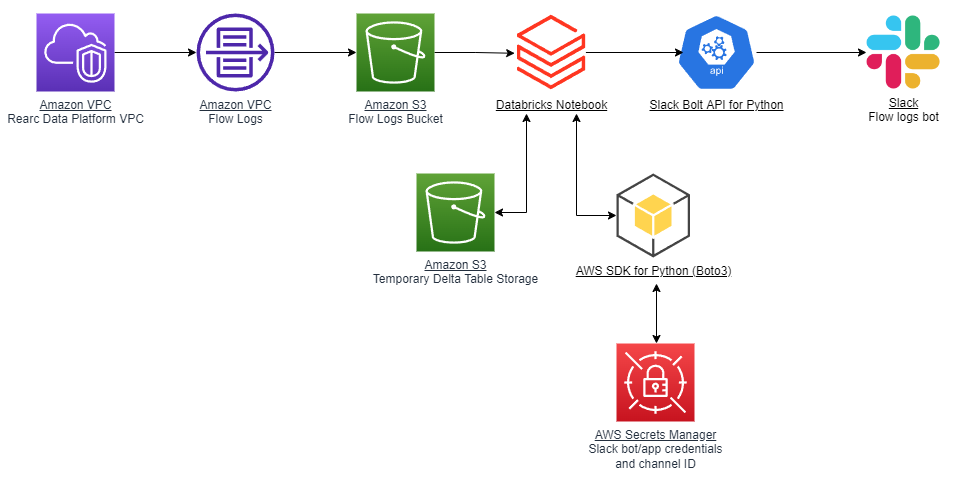
The architecture diagram above describes my final major project. The goal is to take VPC flow logs from Rearc's data platform, run SQL queries against the data for making visualizations, and send the visualizations to a Slack channel using a Slack bot. This data analysis would run on a daily basis to send insights from the previous day's flow logs.
Here's a high-level overview of the steps involved in the pipeline:
.parquet files (implemented using AWS CDK)"Monitor AWS Network Traffic with VPC Flow Logs using Cloudwatch and AWS CDK" is my first technical publication. It helped refine my technical writing skills.
I received several accreditations and a certification during the internship:

Rearc provided educational support with relevant course lectures and practice exams. Not only was I able to learn but now I can apply this knowledge to real-world projects.
I'll be focusing on my course work for university during the upcoming semesters and leveraging the skills that I've learned to explore new fields and projects. I am thankful to have taken my first step forward in my professional career with Rearc, and look forward to what the future holds.
Read more about the latest and greatest work Rearc has been up to.
LLM applications have a semi-infinite attack surface, and they are notoriously hard to secure without breaking the user experience.

Recently, articles surrounding the supposed dangers of an open source abliteration tool called Heretic, along with legal notice being served to its creator, have inspired me to speak out for two reasons.
A step-by-step guide to deploying a Databricks workspace with Private Service Connect (PSC) on GCP and common pitfalls to avoid.

A deep dive into Databricks Foreign Catalogs for Glue Iceberg table access
Tell us more about your custom needs.
We’ll get back to you, really fast
We will evaluate your query and respond within 2 business days.
Kick-off meeting
We will schedule a quick meeting to further understand your use case and start working toward a solution together!