
Red Agent Swarms for Testing Customer-Facing AI Agents
LLM applications have a semi-infinite attack surface, and they are notoriously hard to secure without breaking the user experience.
AI
LLM
AI Safety

How to streamline a deployment pipeline being bogged down by container bloat
All developers have been there. They fire up their development pipeline for the 4th time in a row just to test a small change that is failing in one of the last steps. Unfortunately, the base container image used in this pipeline has grown bloated and now builds are taking significant time. It would be nice to move some of the static files out of the application container and to a backend storage, but management has made it clear that performance and cost savings are paramount.
In an effort to alleviate this pain from a particular development group, a DevOps team I worked with was able to leverage existing capabilities within Amazon Elastic Container Service (ECS). The idea was to divorce the static files from the application code, but in a way that kept the static files local to the application.
(It should be noted that this works best with Fargate as the backend for the containers, but may still be applicable with EC2 backends)
When creating ECS Task Definitions, it is generally a good idea to keep it simple. Even AWS best practices recommend avoiding use of multiple containers per Task. However, the main advantage (both containers running on the same physical machine) is something we can leverage.
If we take all static files that rarely change from release to release and move them into a separate "data" container, we can now keep our application lean. And since ECS natively supports multi-container Task Definitions, the setup is simple.
Say your original application Dockerfile looks something like this:
FROM nginx:latest
# Add the static files
COPY ./html_directory /usr/share/nginx/html
RUN apt-get update && apt-get install --no-install-recommends -y nginx; \
echo "daemon off;" >> /etc/nginx/nginx.conf
COPY entrypoint.sh /entrypoint.sh
RUN chmod +x /entrypoint.sh
ENTRYPOINT ["/entrypoint.sh"]This can be changed slightly to avoid pulling in the static files:
FROM nginx:latest
RUN apt-get update && apt-get install --no-install-recommends -y nginx; \
echo "daemon off;" >> /etc/nginx/nginx.conf
COPY entrypoint.sh /entrypoint.sh
RUN chmod +x /entrypoint.sh
ENTRYPOINT ["/entrypoint.sh"]And then just move your static files to a new repository and create a "data" Dockerfile to load those in a volume:
FROM alpine:latest
COPY html_directory /usr/share/nginx/html
VOLUME ["/usr/share/nginx/html"]Your current Task Definition should be similar to:
{
"taskDefinitionArn": "arn:aws:ecs:us-east-1::task-definition/single-container-task:5",
"containerDefinitions": [
{
"name": "nginx",
"image": <your bloated application image>,
"cpu": 0,
"portMappings": [
{
"name": "nginx-80-tcp",
"containerPort": 80,
"hostPort": 80,
"protocol": "tcp",
"appProtocol": "http"
}
],
"essential": true,
"environment": [],
"environmentFiles": [],
"mountPoints": [],
"volumesFrom": [],
"startTimeout": 20,
"stopTimeout": 120,
"ulimits": [],
"logConfiguration": {
"logDriver": "awslogs",
"options": {
"awslogs-group": "/ecs/single-container-task",
"awslogs-create-group": "true",
"awslogs-region": "us-east-1",
"awslogs-stream-prefix": "ecs"
},
"secretOptions": []
},
"systemControls": []
}
],
"family": "single-container-task",
"taskRoleArn": "arn:aws:iam:::role/ecs-task-ecr-read",
"executionRoleArn": "arn:aws:iam:::role/ecs-task-ecr-read",
"networkMode": "awsvpc",
"revision": 5,
"volumes": [],
"status": "ACTIVE",
"requiresAttributes": [
{
"name": "com.amazonaws.ecs.capability.logging-driver.awslogs"
},
{
"name": "ecs.capability.execution-role-awslogs"
},
{
"name": "com.amazonaws.ecs.capability.ecr-auth"
},
{
"name": "com.amazonaws.ecs.capability.docker-remote-api.1.19"
},
{
"name": "com.amazonaws.ecs.capability.task-iam-role"
},
{
"name": "ecs.capability.container-ordering"
},
{
"name": "ecs.capability.execution-role-ecr-pull"
},
{
"name": "com.amazonaws.ecs.capability.docker-remote-api.1.18"
},
{
"name": "ecs.capability.task-eni"
},
{
"name": "com.amazonaws.ecs.capability.docker-remote-api.1.29"
}
],
"placementConstraints": [],
"compatibilities": [
"EC2",
"FARGATE"
],
"requiresCompatibilities": [
"FARGATE"
],
"cpu": "256",
"memory": "1024",
"runtimePlatform": {
"cpuArchitecture": "X86_64",
"operatingSystemFamily": "LINUX"
},
"tags": []
}To change the definition, we simply need to add the "data" container and define the volume locations:
{
"taskDefinitionArn": "arn:aws:ecs:us-east-1::task-definition/multi-container-task:2",
"containerDefinitions": [
{
"name": "nginx",
"image": <your lean application image>,
"portMappings": [
{
"name": "nginx-80-tcp",
"containerPort": 80,
"hostPort": 80,
"protocol": "tcp",
"appProtocol": "http"
}
],
"essential": true,
"environment": [],
"environmentFiles": [],
"mountPoints": [],
"volumesFrom": [
{
"sourceContainer": "data_source",
"readOnly": false
}
],
"dependsOn": [
{
"containerName": "data_source",
"condition": "SUCCESS"
}
],
"ulimits": [],
"logConfiguration": {
"logDriver": "awslogs",
"options": {
"awslogs-group": "/ecs/",
"awslogs-create-group": "true",
"awslogs-region": "us-east-1",
"awslogs-stream-prefix": "ecs"
},
"secretOptions": []
},
"systemControls": []
},
{
"name": "data_source",
"image": <your data image>,
"portMappings": [],
"essential": false,
"environment": [],
"environmentFiles": [],
"mountPoints": [
{
"sourceVolume": "nginx_data_source",
"containerPath": "/usr/share/nginx/html",
"readOnly": false
}
],
"volumesFrom": [],
"systemControls": []
}
],
"family": "multi-container-task",
"taskRoleArn": "arn:aws:iam:::role/ecs-task-ecr-read",
"executionRoleArn": "arn:aws:iam:::role/ecs-task-ecr-read",
"networkMode": "awsvpc",
"revision": 2,
"volumes": [
{
"name": "nginx_data_source",
"host": {}
}
],
"status": "ACTIVE",
"requiresAttributes": [
{
"name": "com.amazonaws.ecs.capability.logging-driver.awslogs"
},
{
"name": "ecs.capability.execution-role-awslogs"
},
{
"name": "com.amazonaws.ecs.capability.docker-remote-api.1.19"
},
{
"name": "com.amazonaws.ecs.capability.ecr-auth"
},
{
"name": "com.amazonaws.ecs.capability.task-iam-role"
},
{
"name": "ecs.capability.container-ordering"
},
{
"name": "ecs.capability.execution-role-ecr-pull"
},
{
"name": "com.amazonaws.ecs.capability.docker-remote-api.1.18"
},
{
"name": "ecs.capability.task-eni"
},
{
"name": "com.amazonaws.ecs.capability.docker-remote-api.1.29"
}
],
"placementConstraints": [],
"compatibilities": [
"EC2",
"FARGATE"
],
"requiresCompatibilities": [
"FARGATE"
],
"cpu": "256",
"memory": "1024",
"runtimePlatform": {
"cpuArchitecture": "X86_64",
"operatingSystemFamily": "LINUX"
},
"tags": []
}When this new task runs, the following occurs:
The main advantage is that our application should be much leaner, allowing for code changes to build faster. While dealing with small to medium images, a user is unlikely to notice a difference, here are some example times once we start increasing that size.
| Size | Build time |
|---|---|
| 150 MB | 8.73s |
| 750 MB | 44.66s |
| 2.25 GB | 147.53s |
Of course, each project should be evaluated separately based on their own build times and build frequencies. But if your static files are a significant portion of the container image, the cumulative effect can be game changing.
First, let us mention what we are not sacrificing: application performance or scale-up time.
Here is an example of the results of load tests against the two setups, and regardless of file size, there was never an appreciable difference:
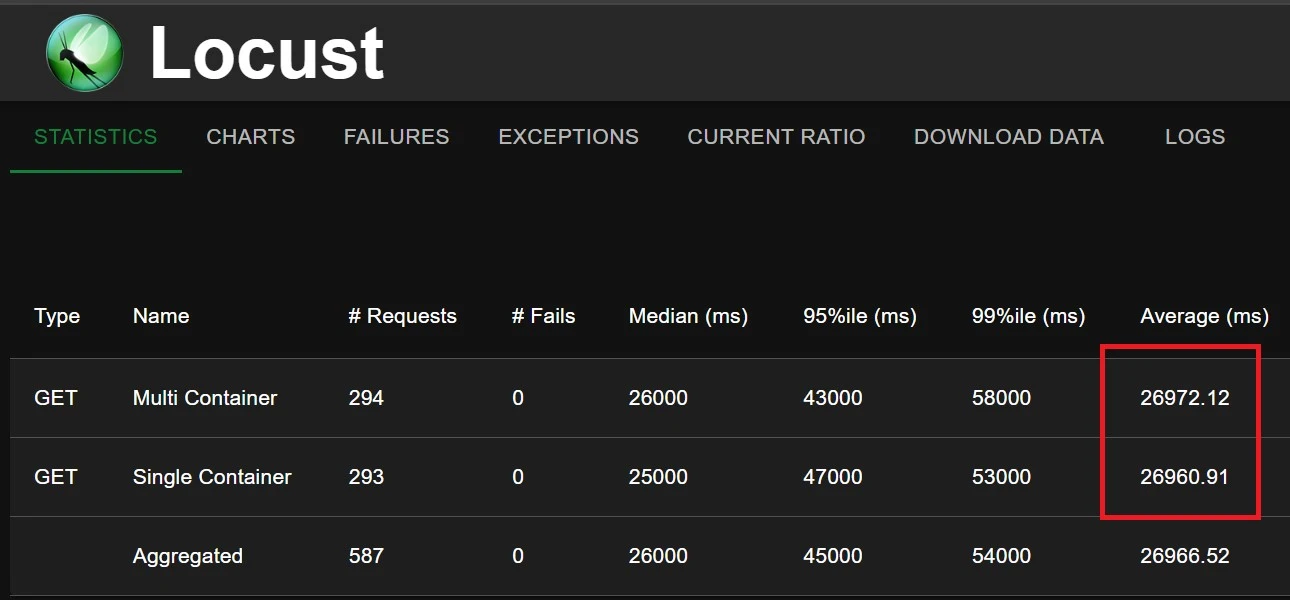
For scale-up times, the multi-container setup showed no difference regardless of the size of the static files (tested from 80mb to 300mb)
The main cost comes from the added deployment complexity. There will now need to be a pipeline that has two repositories as inputs and several design questions follow from that:
How these questions get answered can vary from project to project.
There are other ways to keep the application container lean, but this multi-container method compares favorably to those.
With an EFS mount your entire ECS Task can be pared down to a lean container image, which would maximize the speed of Task scale-up. However, your Tasks now require reaching over a network to access their static files, which introduces I/O latency and transfer costs. Additionally, EFS itself is an opaque data source which requires extra steps to view and update files. It has no built-in versioning/history like data in a repository would.
An S3 solution would require one of the following approaches:
Though this approach does require some refactoring of the application and build process, the downsides are limited. Ultimately, the scenario where this approach would add the most value is having a pipeline fast enough that our developers are watching the build actively instead of a pipeline that has them context switching to answering emails or other distractions. Even our DevOps processes must compete in the attention economy!
Read more about the latest and greatest work Rearc has been up to.
LLM applications have a semi-infinite attack surface, and they are notoriously hard to secure without breaking the user experience.

Recently, articles surrounding the supposed dangers of an open source abliteration tool called Heretic, along with legal notice being served to its creator, have inspired me to speak out for two reasons.
A step-by-step guide to deploying a Databricks workspace with Private Service Connect (PSC) on GCP and common pitfalls to avoid.

A deep dive into Databricks Foreign Catalogs for Glue Iceberg table access
Tell us more about your custom needs.
We’ll get back to you, really fast
We will evaluate your query and respond within 2 business days.
Kick-off meeting
We will schedule a quick meeting to further understand your use case and start working toward a solution together!